
I'm Not A Robot (reCaptcha alternative)
In this post I will share my thoughts on a captcha-free alternative that focuses on simplicty and user experience
What is CAPTCHA?
CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart) is a service that promotes protection of your websites from spam and unwanted content entries from bots. CAPTCHA is a kind of test that helps determine with a degree of certainty if an entry is from a human or a bot
Why Would A Developer Not Opt To Use CAPTCHA
CAPTCHA sounds amazing and resourceful, why wouldn't developers want to implement this strategy? After all, this is more about protecting data integrity and the website infrastructure than it is the end-user.
There are many reasons why this particular security flow is not right for you, but I'll touch on what I think are the predominate contributors:
- Horrible User Experience (UX)
- See the W3C's confirmation of said UX regarding accessibility issues and overall CAPTCHA effectiveness
- False negatives for users that depend on accessibility features
- reCAPTCHA can even at times redirect a user to an external site to validate
- It's not a proper solution for users who don't allow cookies or disable JavaScript (this is becoming more frequently used as a tactic to circumvent adblockers and ads in general)
- Users may be deemed a 'risk' if they are using increasingly adopted privacy obfuscation techniques like VPNs and prompted to prove they are not a robot as a direct result
- CAPTCHA has and always has been useless because spambots have evolved (hence the reason reCAPTCHA was born). In fact, the new version which is supposed to be a sophisticated bot identification algorithm, is nothing but a mere usage of browser cookies
- Even if you select the appearingly simple "I'm not a robot" checkbox, you still may be identified as a risk and be prompted to prove that you are not
- Using services like Google's reCAPTCHA - the cost of users privacy doesn't out-weigh the totality of protection for both parties
- Google specifically violates GDPR by aggregating user data for advertisement (what's new?)
The user knows they want to send a form after they have completed it, they also know they are not robots, so it's redundant and counterintuitive to make the user prove they are human as opposed to making a bot prove they are not a bot. We shouldn't be penalizing users to protect our sites
Does My Site Need CAPTCHA?
There really is no good answer to this because it's dependent on so many variables and respective needs. I think, at minimum, websites always need a layer of protection for spambots but to really determine if CAPTCHA is necessary or right for you, it wouldn't hurt to do some A/B Testing.
Most importantly, as pointed out by some reputable resources, CAPTCHA has been proven to be an ineffective method for thwarting spambots; so I caution to not recommend it at all but the data reflects its usefulness. Ultimately, it's something you should consider after you consider how it affects your users and total cost of ownership of your development cycle.
Alternatives
Inline Actions to Submit
Users ultimately have to interact with some kind of control to submit a form, usually in the form of a dedicated button.
This alternative approach is simple - by forcing the user to do 'complex' human behavior actions in conjunction with submitting. It is intuitive enough that humans inherently perform the action but obfuscated enough that robots are confused by it. Most importantly, it's a process that is inline with the natural order of processes; meaning, it doesn't take an additional step or require the users to go out of their way to validate themselves prior to submitting a form.
Let's look at the submit button as it's normally implemented:
If we make this interaction more complex we can have a degree of assurance that it is a human doing the action - but we can still do it in a way that doesn't take away from the natural order and doesn't require additional user feedback.
A crude example of an inline 'complex' action could be something like 'slide to submit':
const input = document.querySelector('input');
input.onmouseup = ({ target }) => {
if (target.valueAsNumber === 100) {
//success
}
}This concept can be elaborated on by dynamically generating a range each time the page is loaded and the user will have to adjust accordingly:
<div id="slider-submit" class="container">
<div> </div>
<input type="range" value="0" />
</div>#slider-submit {
position: relative;
height: 30px;
}
#slider-submit div {
position: absolute;
width: 20%; height: 20px;
top: 10px;
border: 4px solid red;
border-top: none;
border-bottom: none;
}
#slider-submit div::after {
content: "SUBMIT";
position: absolute;
width: 100%;
bottom: -15px;
text-align: center;
}
#slider-submit input {
position: absolute;
width: 100%;
margin: 0;
}
const random = (min, max) => {
return (Math.random() * (max - min) + min) | 0;
};
const slider = document.querySelector("#slider-submit input"),
submitRange = document.querySelector("#slider-submit div"),
submitWidth = random(8, 18),
submitPos = random(5, 100 - submitWidth);
submitRange.style.width = `${submitWidth}%`;
submitRange.style.marginLeft = `${submitPos}%`;
slider.onmouseup = ({ target : { valueAsNumber }}) => {
if (valueAsNumber >= submitPos && valueAsNumber <= submitPos + submitWidth) {
//success
}
};
You could even make it fun by incorporating your website's theme. For example, if you have a website about board games/video games you could ask the user to 'beat' a game in order to submit:
Naturally you'll have to implement additional logic to ensure these values aren't being changed programmatically, but these examples are just to demonstrate intent. You can take this design philosophy in so many directions.
Time Based
Time based forms is an alternative which is hidden from users, the perfect user-experience scenario. The idea behind this is to detect a spambot based on the time it takes to complete a form (forms submitted in under 30 seconds of the page loading are typically spam). Legitimate human interaction will take no less than 45 seconds, depending on the substance of your form of course, whereas spambots submit forms instantaneously. Therefore, a form submitted too quickly would be identified as high risk.
It would be important to note that you should ensure auto-filling and persistence is not a factor in this solution.
Contrary to this, you don't want a form to take too long, for bots or humans. There should be measures to protect against this as well, but specifically for spambots because they can 'save' fields for later and perpetually send submissions until it is successful.
Detect JavaScript
If your page is running JavaScript, you can be almost certain it has been loaded in a browser by a human user. An in-page dynamically generated JavaScript function could perform a simple calculation or create a checksum for the posted data. This can be passed back in a form value for verification.
An estimated 10% of people have JavaScript disabled, so further checks will be necessary in those situations.
Some bots can read and understand JavaScript but this simple addition to your arsenal takes little effort to include for the reward. It will still restrict a majority of spambot scenarios.
You can easily identify in pure HTML if a user has JavaScript enable by using the <noscript> tag:
<form>
<noscript>
<input type="text" name="noscript" class="hidden"/>
<noscript>
</form>
You could then replace the noscript element with your JavaScript checksum control when it's enable
Honeypot
Honeypot is a direct solution that focuses on intentionally baiting bots. Honeypot, when done correctly, is one of the most effective techniques to-date.
Honeypot effectively means to trick the bot into filling out a field that a user normally wouldn't, it's usually hidden from users for that reason. If it's filled out or included in the form submission in any way you can be certain it's due to malicious intent.
Of course the honeypot method can be circumvented just like anything by the more mature spambots, but the key is to not be predictable for maximum effectiveness, or in some cases being obviously predictable. For example, make it look like a legitimate field with a label and name it something obvious like 'password' to bait spambots to fill it out.
<form>
<label>Enter your password bot:
<input class="form-foobar" type="password" name="password" />
</label>
</form>.form-foobar {
border: 0;
clip: rect(0 0 0 0);
height: 1px;
margin: -1px;
overflow: hidden;
padding: 0;
position: absolute;
width: 1px;
}
Notice how the example above does not use the proper 'hidden' attribute, instead it should be hidden via CSS or JavaScript for obvious reasons (JavaScript is highly recommended though).
Just like the other alternatives, this is just a simple crude example, but you can take this in so many directions as well. Remember, the key for honeypot is to intentionally attract bots and bait them to fill out controls that would flag them, but don't be consistent with integration and don't code it for humans (i.e., obfuscate nomenclatures and naming conventions)- and it will easily take care of the majority of spambot traffic.
Heuristics
Heuristics is the study or practice of a given procedure, related to self-educating techniques.
In a nutshell, heuristics is learning your user's behavior and applying a standard to that behavior. This is not as forgiving as other solutions on developers but once implemented to fit your needs it's a staple of protection.
A good starting point for heuristics is with every form submission you should persist the users IP. In the case that there are rapidly subsequent submissions from the same IP then you should ban future requests from that IP. It's possible that there would be edge cases where a human could do this unintentionally but once you consider other behavior patterns you can almost certainly deduce if it's a human or not.
function getIPAddress() {
if(!empty($_SERVER['HTTP_CLIENT_IP'])) $ip = $_SERVER['HTTP_CLIENT_IP'];
elseif (!empty($_SERVER['HTTP_X_FORWARDED_FOR']))
$ip = $_SERVER['HTTP_X_FORWARDED_FOR']; //proxy
else $ip = $_SERVER['REMOTE_ADDR'];
return $ip;
}
$ip = getIPAddress();
There is a caveat to solely depending on the IP approach - VPN & and Proxies. Also, for example, think about public Wi-Fi at a mall; you don't want to penalize all users because someone went to the mall specifically to not be identified by their home IP. So you should use caution in how you approach this, but best case scenario, this would still be resourceful to rate limiting requests.
Another behavior from spambots is that they normally submit forms instantaneously. So with the auditing features like tracking IP plus understanding how long it took to submit an additional request you can collectively make a sound decision.
Spambots will also not fill out headers. Not all of them commit to this practice but it's healthy to verify that these are filled out to eliminate illformed requests. The following is an example of common headers you should be expecting naturally as part of the request:
function isHeadersSet() {
return !(empty($_SERVER[‘HTTP_USER_AGENT’])
|| empty($_SERVER[‘REMOTE_ADDR’])
|| empty($_SERVER[‘HTTP_ACCEPT’])
|| empty($_SERVER[‘HTTP_ACCEPT_LANGUAGE’]));
}
Additionally, you could validate the host is from your website, as most forms should be sent from your website anyways. Additionally, you should verify that the HTTP Method is the expected HTTP method - a good indicator of a spambot that just relies on web scraping. Meaning, if a spambot just quickly pings all response method types just to see which one hits (GET, POST, HEAD etc), you should know something is suspicious at that time.
if ($_SERVER['REQUEST_METHOD'] !== 'POST') {
http_response_code(405);
exit();
}
Spambots will also simply just include erroneous parameters in POST and GET requests simply to include commonly used parameters just in case they are expected in the request. You should take this into consideration when implementing your logic and validate you are only receiving the parameters you are expecting. It is VERY rare, that your form should include any additional parameters from a human if they fill it out properly. The only way it does is if a human is intentionally looking for security holes using Postman or ARC or some other request software. Even when that's the case, you will still be receiving more parameters than you expect so you should send a non-satisfactory response regardless.
function urlContainsErroneousParameters() {
parse_str($_SERVER['QUERY_STRING'], $params);
if (count($params) > 0) return true;
$expected = array( 'name', 'email', 'comment');
return count(array_diff(array_keys($_POST), $expected)) > 0;
}
if (!isHeadersSet() || urlContainsErroneousParameters()) {
exit("Error");
}
Again, this requires a careful examination of site data and to be properly implemented. If pattern-matching algorithms can’t find good heuristics, then this is not a good solution for your scope.
Web Components (HTML5 & JavaScript Custom Elements only - no frameworks)
This is something I personally use in my solutions but it's worth mentioning as a stand-alone alternative because it's a really resourceful technique and rarely used outside the scope of frameworks.
A custom element in HTML5 is basically your own way of creating your own HTML tag, and in some cases take advantage of the D.R.Y. philosophy by instantiating it with frequently used markup.
For a crude example let's say instead of using a <p> tag you want a paragraph element where the text is always green. You would simply name it 'green-paragraph' and define it for the browser to render:
<my-green-paragraph>Hello World</my-green-paragraph>
customElements.define('my-green-paragraph',
class extends HTMLElement {
constructor() {
super();
this.style.color = 'green';
}
}
);
As you can see it's quite easy to extend HTML elements and not much work for a developer to implement.
You could even take time to obfuscate access to these elements even more by using a closed shadowDOM
What does this mean in context to the topic at hand? Most spambots are looking for very specific syntax, for input's they would query the DOM like a regular consumer: document.querySelector('input[type="text"]');
Let's first emulate what someone may see by making a server request to this HTML:
curl -uri http://localhost:5500/input-example.html
# output:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Input Example</title>
</head>
<body>
<form action="validate.php">
<input type="text" placeholder="Enter value here">
<button type="Submit">Submit</button>
</form>
</body>
</html>
As shown, you get all the markup you would expect, and could also see that using the querySelector methods are trivial in obtaining the information you want.
However, if you were to use custom web components/elements, you can't query it and access it, per normal conventions. First you would have to know the nomenclature of a given website's naming convention and then you may or may not have easy access to the internals depending on the fallbacks in place. So in this example let's say we named our input something like <form-input></form-input>, it is clearly something spambots would need to account for at scale and would have to be clever in navigating those use-cases since the naming conventions are arbitrary and websites create and use them in their own unique way.
Let's visualize how this works. Attach a shadowDOM to the custom element and mark it as closed. Note, there are still ways to get around closed shadowDOMs, but it's about not being predictable and not making it easy:
class FormInput extends HTMLElement {
constructor() {
super();
const shadow = this.attachShadow({ mode: 'closed'});
const input = document.createElement('input');
input.placeholder = 'Enter value here';
shadow.append(input);
}
}
customElements.define('form-input', FormInput);
Then for the HTML, you just call the form using the name you defined above:
<form>
<form-input></form-input>
</form>
As you can see in the developer tools inspector image below, the custom element doesn't show the input tag as a direct child, in fact there is nothing in it at all in this example. You can see that it's attached to the shadowDOM and contains all the markup we gave it at runtime:
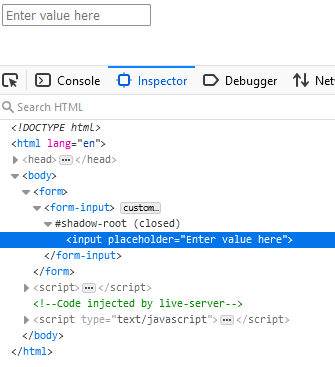
Now if we run the same curl request as before, these elements would not show up in the response body this time, but it's clearly visible in the rendered webpage:
curl -uri http://localhost:5500/custom-input-example.html
# output:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Custom Input Example</title>
</head>
<body>
<form action="validate.php">
<form-input></form-input>
</form>
</body>
</html>
Naturally, you can count on spambots to adjust to these changes in due time, but for now, it's a fantastic obfuscation technique to keep you one step ahead. I would highly recommend considering adding this to your developer tool belt regardless because it has so many useful applications outside of form integrity. Extending HTMLElements can really clean up your code and make things easier to maintain by a noticeable margin.
My Solution
Going back to a statement I made earlier - I think we have over time counterintuitively forced the responsibility on users to prove they are human. I would submit it should exclusively be the spambots responsibility to prove that it is not a spambot, give or take a few scenarios.
I do not think there is a single solution to solve this problem. Rather, I think there should be harmonious effort from a mixture of these techniques, at minimum. It may take a little more uptime and development expenses will reflect that but that's how websites should be made. If we want users to come to us, we have to give them reasons to.
Let's think about the natural order of the process again
- A human wants to submit a contact form inquiry. They fill out all the required fields and then are approached (sometimes) with a visual checkbox asking them to click it in order to verify they are human. (There is a noCaptcha variant now that doesn't show a checkbox but this assumes you want to use Google)
- User says to them self, "Self. I am not a spambot, so I should click this to prove it"
- Behind the scenes checks and balances execute and validate and a response is given according to the findings
Now what's obvious is that if a user can check a box, so can a spambot; granted, it's not as easy with CAPTCHA as it's obfuscated but it's not about what the robot can do, in my opinion, it's about what the robot is told to do based on the human condition.
Let me elaborate. A human who coded a spambot tells it the same natural order and codes the control flow around that - "Me human building this bot knows that other humans have to check a box to prove they are human therefore I will code it in such a way that accounts for all the variables around that process as a human faces".
Obviously that is an oversimplification and there is more 'black magic' going on behind the scenes, but the control flow is the same.
So the psychology of submitting user defined data is extremely linear meaning there is a finite amount of ways a spambot can navigate the process based on its instruction catalog.
My solution is to remove that natural order and in some cases reverse it, simply in efforts to confuse spambots and take away what they think is the way we fill out forms as humans.
For example, I rarely use 'click' event handlers when I need to obfuscate processes and use 'pointerup'. Although it's important to note that any window event can be called programmatically; the key is to not use something 'standardized' to obfuscate it enough that it's just weird enough for spambots to not be trained on, and when used in conjunction with other obfuscation tools it creates a strong defense holistically.
For example, using the honeypot strategy in conjunction with hidden nonce fields with time-based prevention strategy and heuristics and simply ensuring there are no erroneous GET or POST parameters present collectively will cover a lot of cases where a spambot can be detected, and then, and only then, if a risk is identified you can prompt the user for some sort of verification practice, otherwise you can assume a bot is trying to manipulate the submission.
I use server-side logic as a tool to dynamically set field names each time the page is loaded so they are not commonly used identifiers that spambots look for like 'email' or 'username' etc. This can also be done in JavaScript (but server-side logic is preferred for obvious reasons)
Additionally, something surprisingly simple is that bots are usually not trained on variants of languages. For example, a bot would normally check if the name of the field is equal to "email".
You can quickly make this more difficult for them by naming the field, or a hidden field, with accents, like 'emáil'.
It's surprisingly simple how you can deceive coders in this regard. I would not personally use this strategy exclusively, but I'm just trying to provide examples on how you should be thinking about this - outside-the-box so to say.
Also to demonstrate that the effectiveness of these bots really depends on the coder, and most coders don't take these characters into consideration. In fact, if you use any normal website like Twitch that consumes comments or chat interaction, you will notice that you can easily get around banned words by using character variants. So if it's something that FAANG companies don't implement you can be assured that for now, spambots are not coded with this taken into consideration.
So my solutions for most of my website needs are usually a mixture of the following:
-
If I'm not using heuristics as a tool, my go-to practice is to instead of asking the human to click a checkbox to prove they are human, I will intentionally include a default checked checkbox (spambots will usually see this as a sign that it's required and if it's checked by default will usually translate to 'I want to receive email updates' type of controls which are consistently checked by default).
When the human unchecks it, I can guarantee they are human, but be comfortable enough to know there is an extremely small chance it's a bot.
Furthermore, I will consistently update the name of the control and I will rotate the instructions on the label so that it is never the same across a pattern of time.
Lastly, taking from the thinking outside-the-box idiom, I will not use natural language for my control, meaning instead of using commonly used phrases, I will either change the words around in a way that it doesn't read linearly in addition to swapping characters or including accents, but most importantly to note here is to reverse the natural order process as previously mentioned:
<label> <input type="checkbox" name="consequat-eu-nisi" checked=""/> R0bot not I am. I not rob0t so unchéck this bōx I should. </label> -
Honeypot is most effective when the actual fields used to submit a form use alias names that can be translated on the server side, so that each field looks like a fake to begin with to combat spambots trying to pick out the 'bait' controls.
Additionally I move my hidden fields around so that spambots can not rely on it being in a specific index.
- I always include a hidden bait field, if JavaScript is enabled I will manipulate that field further each time the page is loaded. For example, I will most likely include a password input with the name attribute set to 'password' so spambots are easily attracted to it.
-
If the end-user has JavaScript enabled I will ensure to include a JavaScript checksum in the form.
In cases where the user does not have JavaScript enabled, I will prompt them to enable it temporarily just to submit the form or I will leave it as-is and I will ensure my server-side logic takes extra measures in heuristics analysis for this scenario, depending on what the websites purpose is.
- Re Heuristics; I do make sure at minimum proper form headers are sent and that forms are not submitted within 30 seconds of a page loading and validating they are not including additional GET/POST parameters.
- Lastly, I take my own advice for the submit button inline action. For example, you may have noticed on this websites contact form I have implemented a 'long hold' or 'press and hold' button, this way I can almost be certain that it's a human alone, but of course this is used in conjunction with other tools:
I try to maintain the philosophy of not making the process feel like a chore. Let's be honest, no one likes clicking on images, and the image CAPTCHA can be circumvented anyways, so at least make an effort to encourage somewhat of a fun experience.
You are more than welcome to take and adjust the code for this as you see fit:
<button id="longholdbutton">SUBMIT</button>
class LongPressElement {
constructor(srcElement, milliseconds) {
this.srcElement = srcElement;
const onPointerDownHandler = onPointerDown.bind(this),
onPointerUpHandler = onPointerUp.bind(this),
onPointerCancelHandler = onPointerCancel.bind(this),
onPointerLeaveHandler = onPointerLeave.bind(this),
onPointerOutHandler = onPointerOut.bind(this);
this.srcElement.addEventListener("pointerdown", onPointerDownHandler);
function reset() {
clearTimeout(this.timer);
this.srcElement.removeEventListener("pointerup", onPointerUpHandler);
this.srcElement.removeEventListener("pointerleave", onPointerLeaveHandler);
this.srcElement.removeEventListener("pointerout", onPointerOutHandler);
this.srcElement.removeEventListener("pointercancel", onPointerCancelHandler);
}
function registerEvents() {
this.srcElement.addEventListener("pointerup", onPointerUpHandler);
this.srcElement.addEventListener("pointercancel", onPointerCancelHandler);
this.srcElement.addEventListener("pointerleave", onPointerLeaveHandler);
this.srcElement.addEventListener("pointerout", onPointerOutHandler);
}
function onPointerCancel() {
reset.bind(this).call();
this.srcElement.dispatchEvent(new CustomEvent("longpresscancel"));
}
function onPointerLeave() {
reset.bind(this).call();
this.srcElement.dispatchEvent(new CustomEvent("longpresscancel"));
}
function onPointerOut() {
reset.bind(this).call();
this.srcElement.dispatchEvent(new CustomEvent("longpresscancel"));
}
function onPointerUp() {
reset.bind(this).call();
this.srcElement.dispatchEvent(new CustomEvent("longpresscancel"));
}
function onPointerDown(e) {
if (e.pointerType === "mouse" && e.button !== 0) return;
registerEvents.bind(this).call();
this.srcElement.dispatchEvent(new CustomEvent("longpressstart"));
this.timer = setTimeout(() => {
this.srcElement.dispatchEvent(new CustomEvent("longpressend"));
reset.bind(this).call();
}, milliseconds);
}
}
onLongPressCancel(callback) {
this.srcElement.addEventListener('longpresscancel', callback);
}
onLongPressEnd(callback) {
this.srcElement.addEventListener("longpressend", callback);
}
onLongPressStart(callback) {
this.srcElement.addEventListener("longpressstart", callback);
}
}
const submitBtn = new LongPressElement(document.getElementById('longholdbutton'), 1000);
submitBtn.onLongPressStart(() => {
submitBtn.srcElement.innerText = 'Hold...';
})
submitBtn.onLongPressEnd(() => {
contactForm.submit();
})
submitBtn.onLongPressCancel(() => {
submitBtn.srcElement.innerText = 'Submit';
})Closing Remarks
I discussed some alternatives that give more freedom to legitimate humans so that submitting a form does not feel like a chore, even when it is something fun, like slide to submit, and ultimately only asks to verify in extreme circumstances.
My solutions are not a catchall for spambots, but it covers ~97% of the spam traffic my websites have seen (actual number taken averaged from 4 websites, with low traffic in comparison to other sponsored or advertised websites).
After implementing my solution in the websites I personally manage, I have had 0 spam messages sent to a dashboard or TLD email. Prior to using reCAPTCHA I was getting roughly 1k-1.5k spambot emails a week. With reCAPTCHA I was getting a modest 50-100 spambot emails a month (not that bad). With my holistic solution I have received a total of 7 spam emails in the past 4 months collectively and was able to easily identify how to protect against those in the future.
With that said, I understand spambots will continue to become more observant and sophisticated but for the past 4 months in closely monitoring my implementation I've had nothing but success by my metrics and am pleased to know I can wake up each morning without filtering through annoying spam messages.
There is still much work to be done in regard to finding a one-size-fits-all solution for detecting a human over automated scripts and this will naturally grow harder the more sophisticated computers get and as our mediums evolve (mobile, tablet etc).
It's my opinion the focus should always be on user experience however, regardless of the amount of traffic your website consumes. Naturally, use the best tool for your scope but try to keep in mind the goal is not to penalize active and potential users of your website due to actions robots/crawlers do.
There are numerous techniques in the field that aren't discussed here, especially the ones that focus on user input, like 'Simple Questions' - where a user will have to type the answer to "What is 2+2", for example. Also, there are other alternatives that the W3C recommends like Biometrics, Proof-Of-Work, or Sound; however that is out of scope for casual form needs and intentionally omitted because I wanted the focus to be on alternatives that didn't require an additional step for humans.
I would say that if you are stuck to using CAPTCHA-like functionality, that's okay, but I would recommend not using Googles version, regardless if they make the user experience better in the future, and go with an alternative like hCaptcha or MTCaptcha that don't store and track cross-linking analytics or user data.